Техническа документация: VitaScribe модел за откриване на субтитри
Специализирано решение за компютърно зрение, предназначено да идентифицира и локализира текстови региони във видео кадри. За разлика от стандартния OCR, този модел се фокусира върху високоточната детекция на субтитри, които често имат специфични визуални характеристики — контур, сянка, специфични шрифтове и позициониране. Чрез използването на pipeline за генериране на синтетични данни и архитектурата YOLOv26n, системата постига скорости на inference, подходящи за обработка на видео в реално време.
1. Защо Object Detection за субтитри?
Традиционните подходи за извличане на субтитри разчитат на full-screen OCR — сканиране на всеки пиксел от всеки кадър за текст. Това е изчислително скъпо и води до значителни грешки (false positives) от UI елементи, водни знаци и графики на екрана.
Нашият подход обръща тази парадигма: вместо да сканираме целия екран за текст, първо използваме object detection модел, за да локализираме точния bounding box, където се появяват субтитрите. След това OCR се прилага само върху този малък регион.
Този двустепенен pipeline (Detection → Recognition) предлага няколко ключови предимства:
- Скорост: OCR обработва регион ~200×50px вместо кадър 1920×1080 — приблизително 200× по-малко пиксели.
- Точност: чрез обработка само на потвърдени региони със субтитри елиминираме фалшиви засичания от UI елементи.
- Стабилност: моделът осигурява позиционно закотвяне, което позволява плавно проследяване между кадрите.
2. Теоретична еволюция и предизвикателства
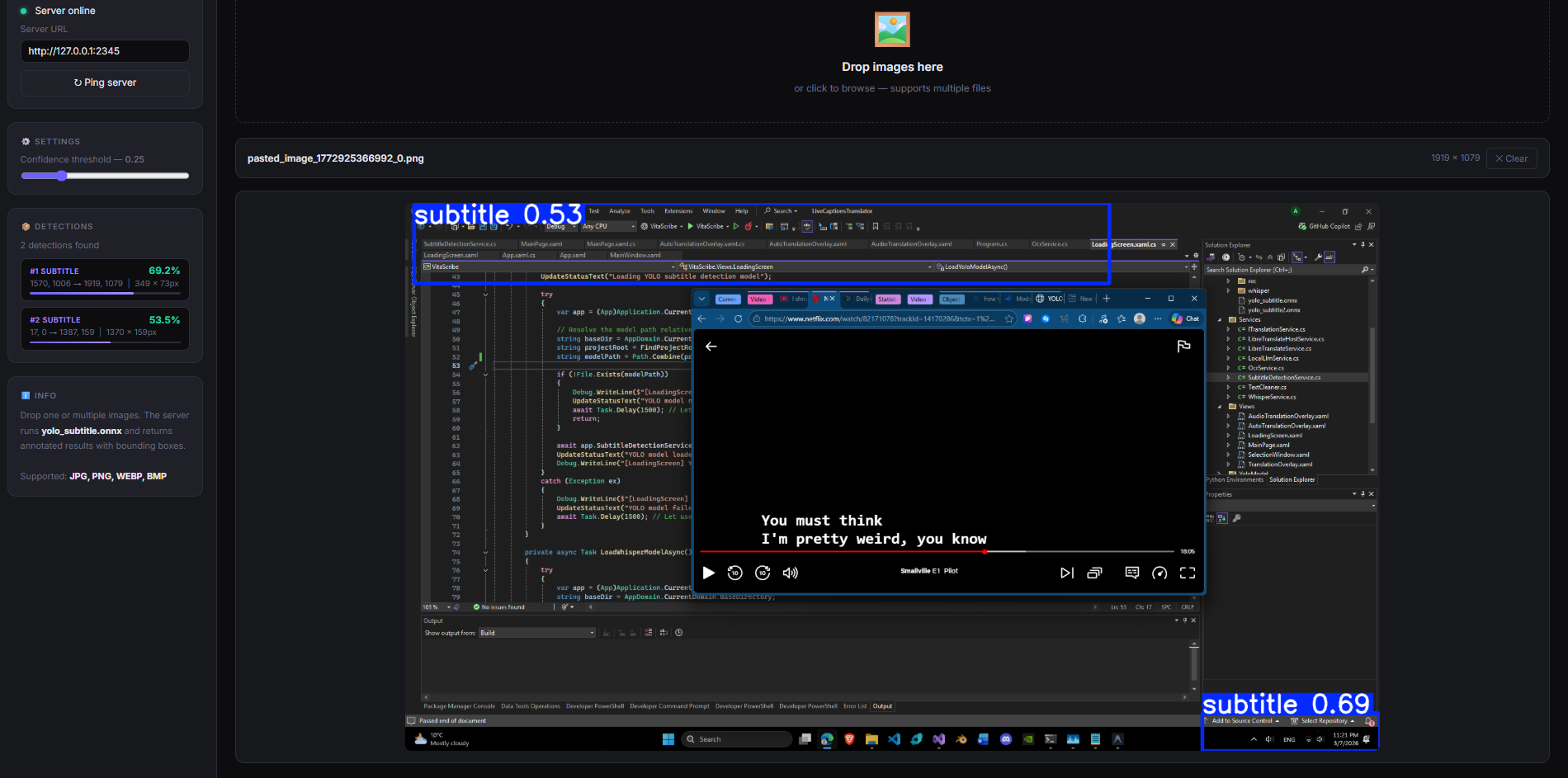
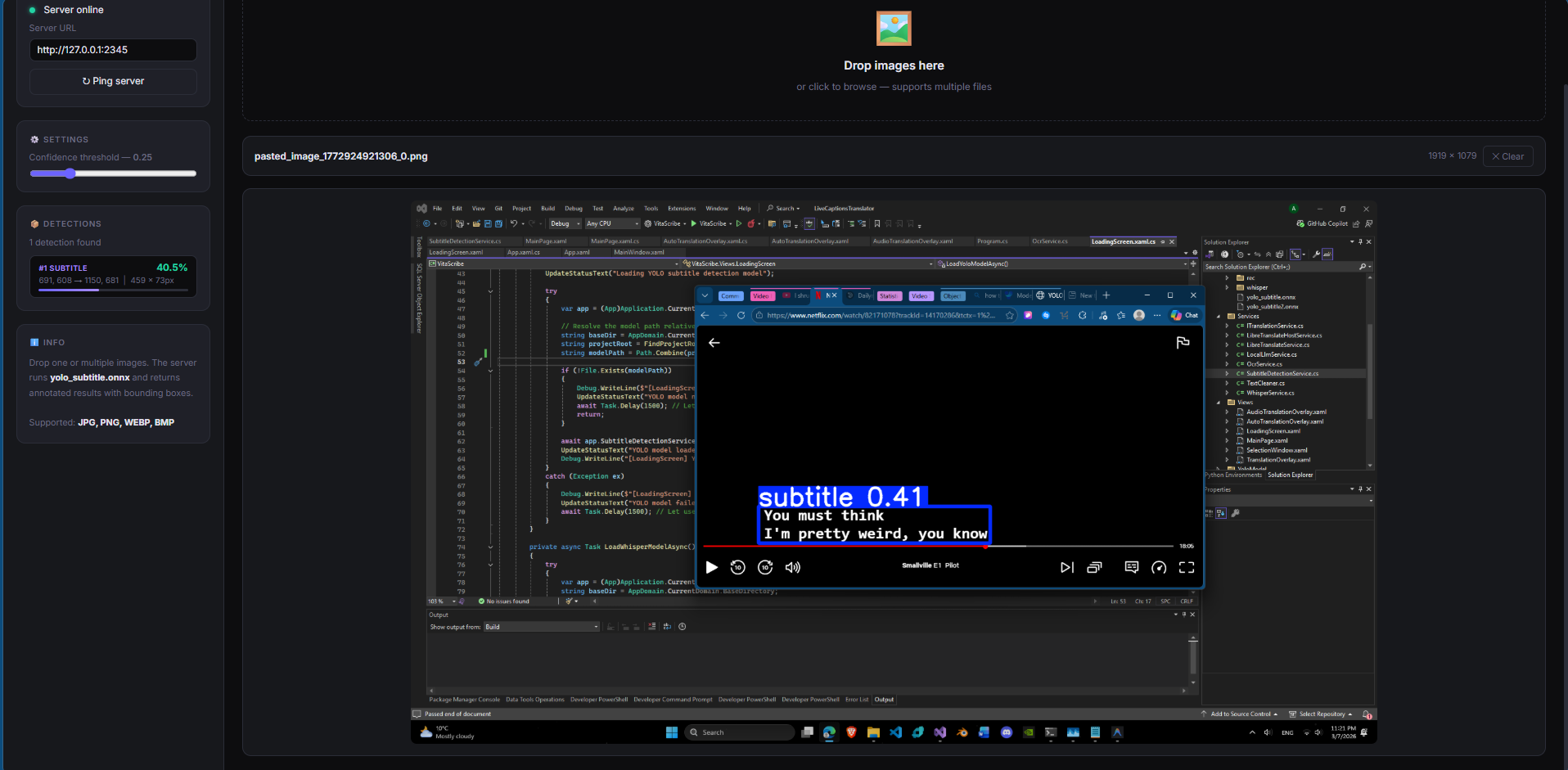
2.1 Проблемът „UI Hallucination“
В ранните версии моделът показваше значителен брой false positives в интерфейсите на видео плейъри.
- Play/Pause бутони и прогрес барове
- Водни знаци и телевизионни лога
- UI менюта и настройки
2.2 Стратегия за подобрение
Hard Negative Sampling
Добавихме 30% кадри със UI елементи, но без субтитри. Това обучава модела какво не е субтитър.
Recursive Fine-tuning
Вместо обучение от нулата използвахме best.pt и извършихме повторно обучение с по-силни аугментации.
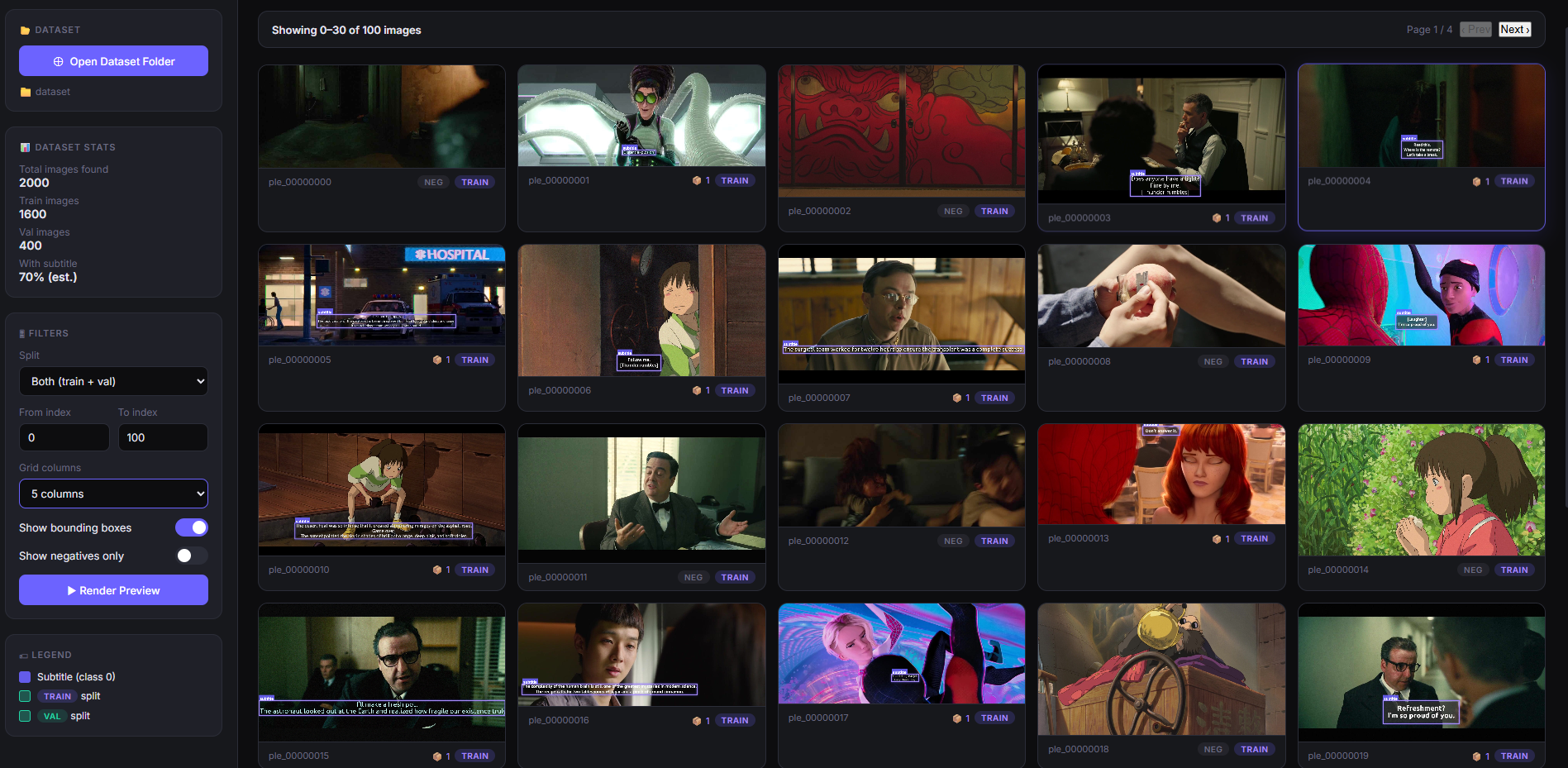
3. Dataset Engineering
Създадохме автоматизиран pipeline за генериране на синтетични тренировъчни данни.
3.1 Synthetic Dataset Preview
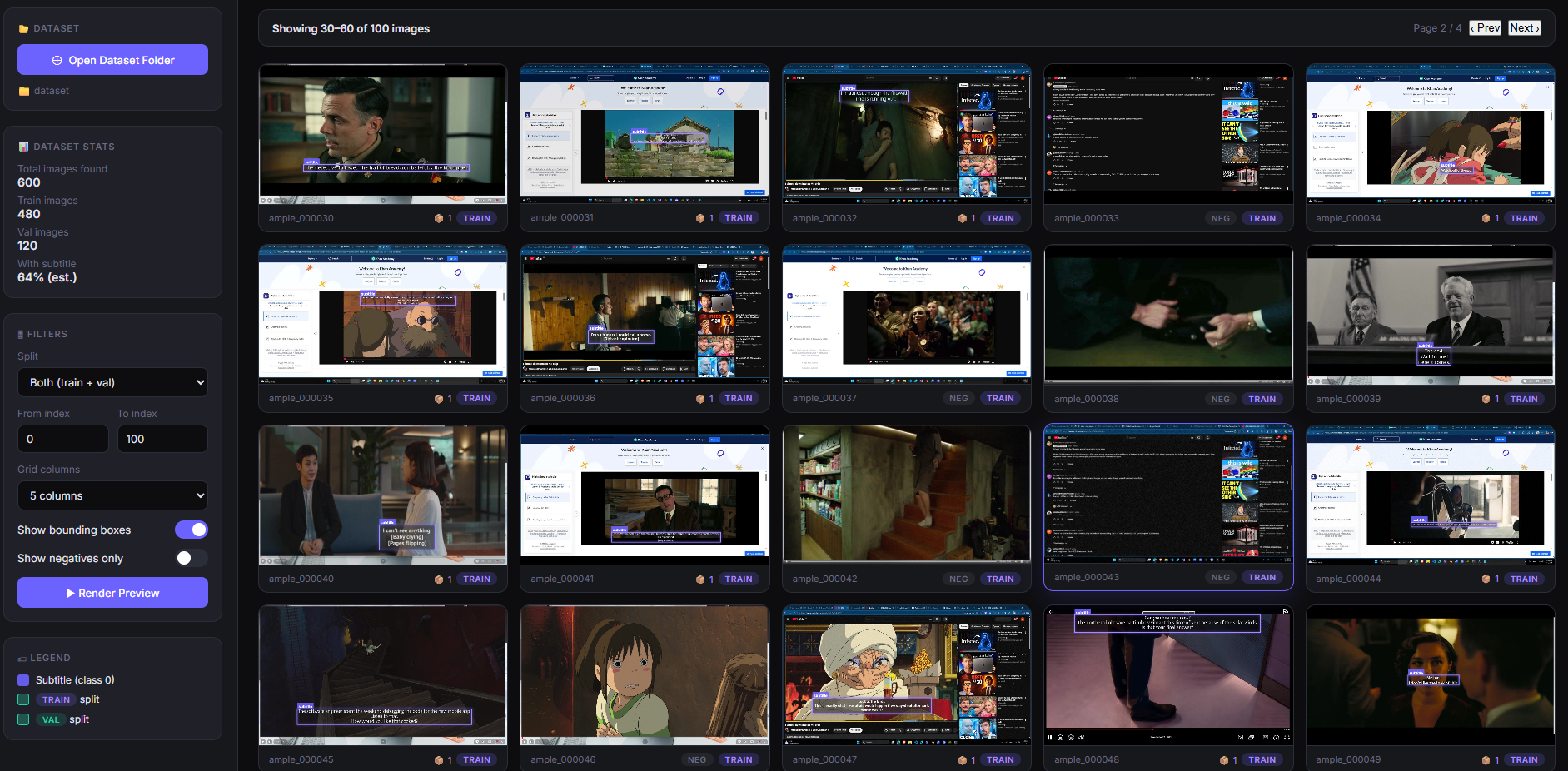
3.2 Training Batch
3.3 Augmentation
Augmentation pipeline включва: resolution jitter, JPEG compression, blur и hard negatives.
4. Резултати от обучението
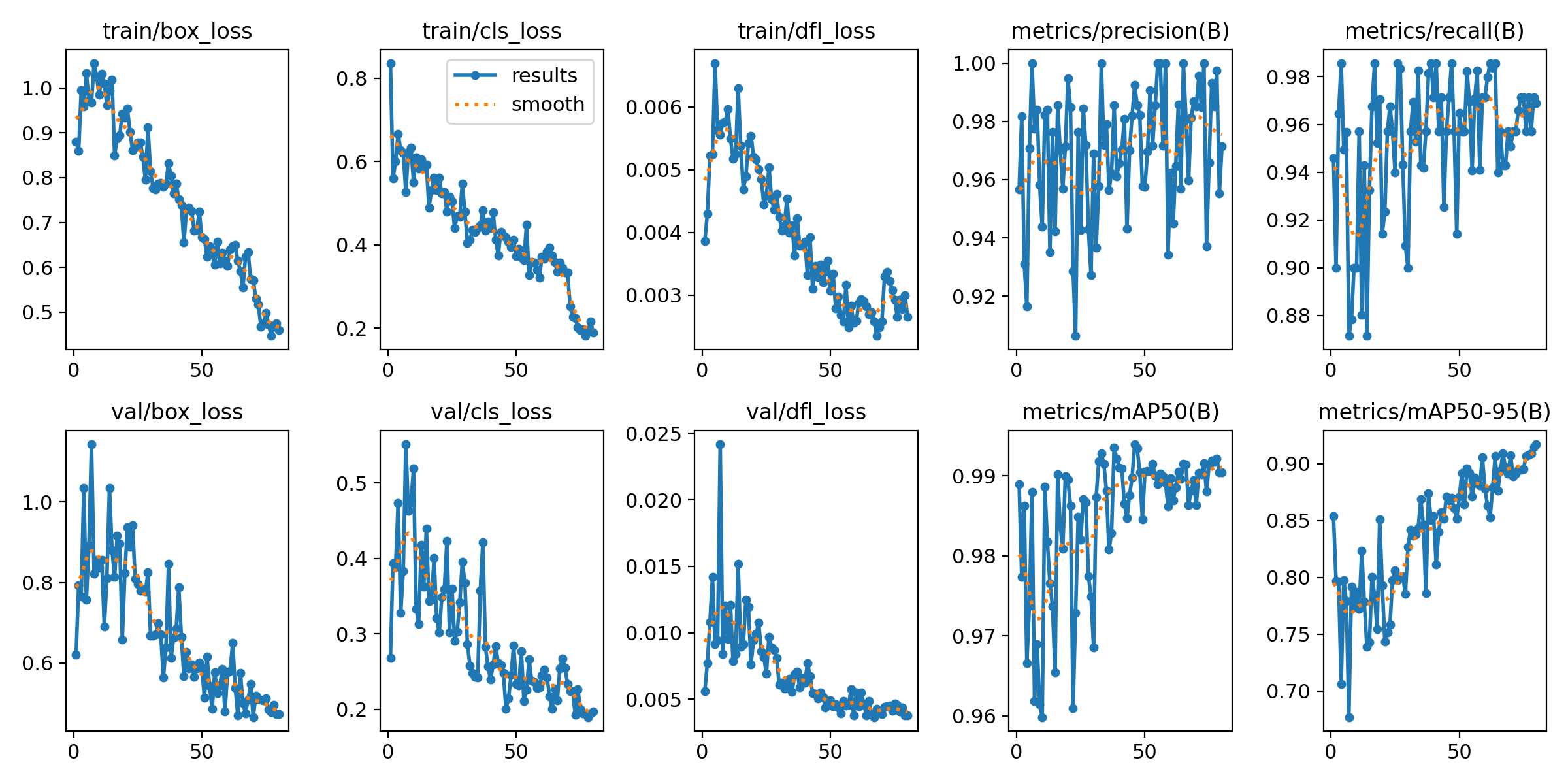
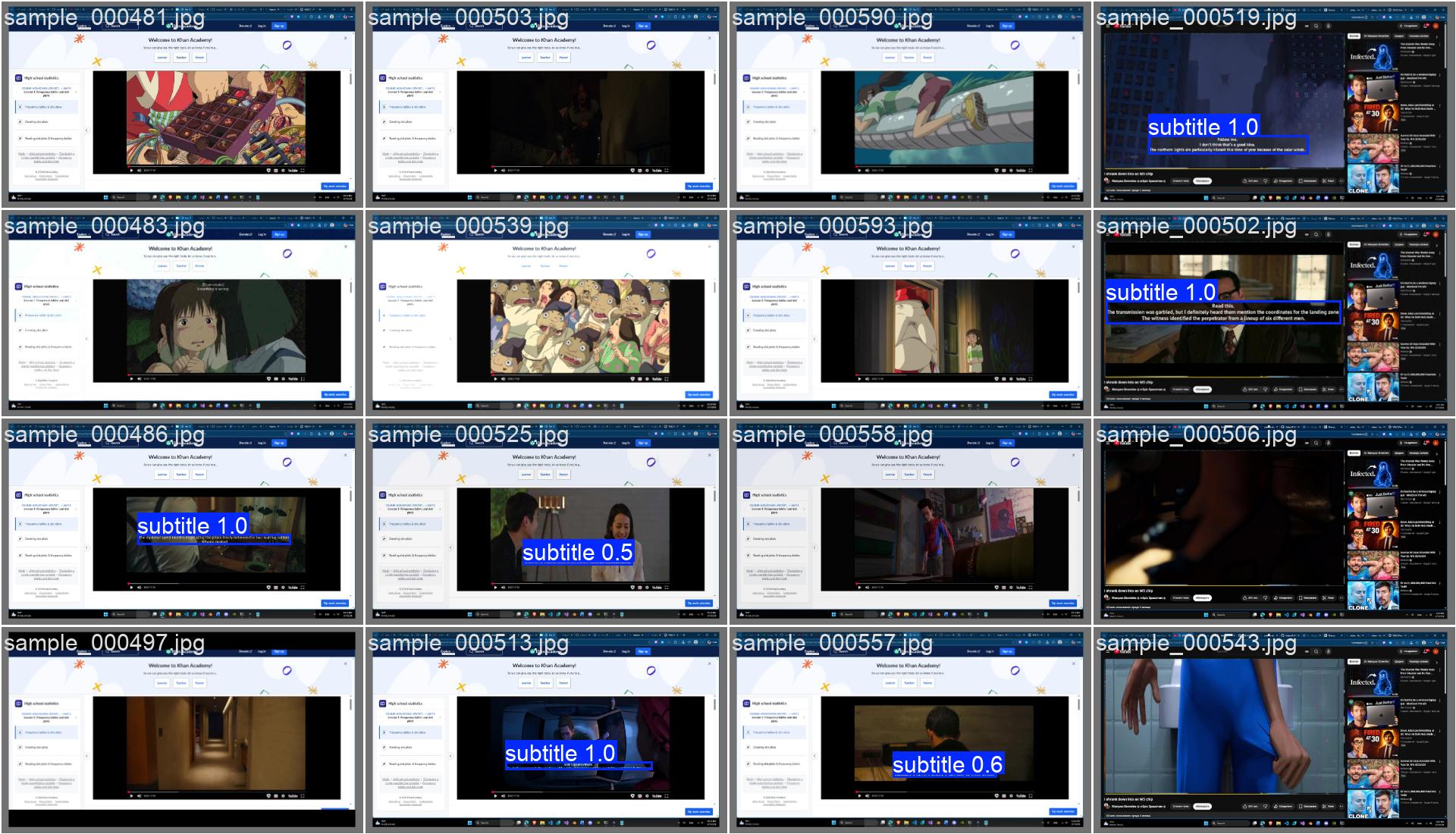
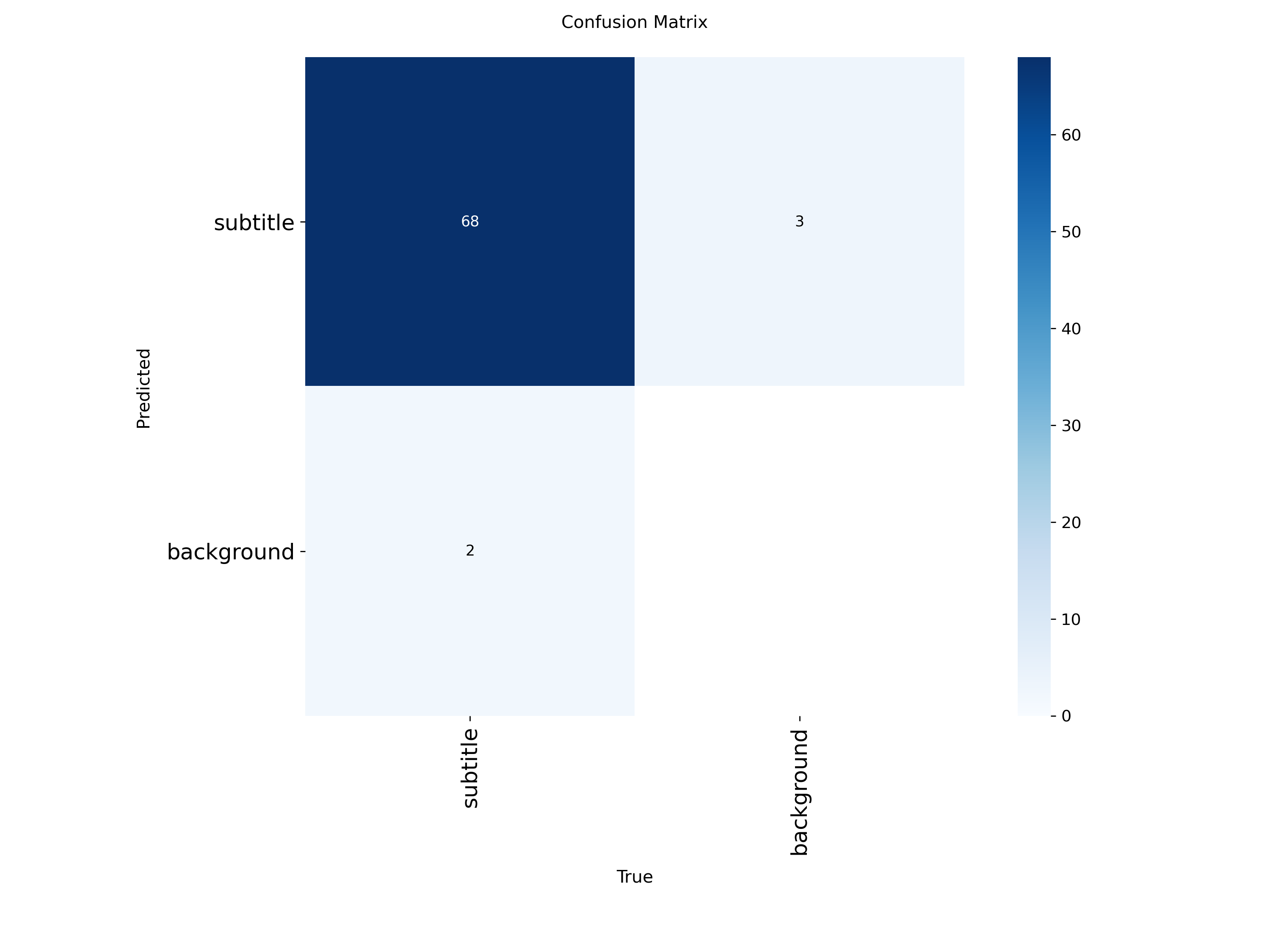
High Recall: моделът открива субтитри дори върху сложни фонове.
Speed: <100ms inference на GPU (RTX 3080 Ti).
5. Deployment Architecture
PyTorch моделът се експортира в ONNX формат за cross-platform inference.
6. Спецификации на модела
| Свойство | Стойност |
|---|---|
| Архитектура | YOLOv26 Nano |
| Framework | Ultralytics YOLO (PyTorch) |
| Формат | ONNX |
| Размер | ~9.3MB |
| Runtime | YOLODotNet + ONNX Runtime (.NET) |
| Latency | <20ms GPU inference |